多种图计算图算法支撑
功能优势

图遍历
基于图中知识节点的深度、 广度遍历计算

路径计算
计算不同知识节点间的路径长度, 可用与相关性的计算

统计计算
可基于图数据,进行标签统计,关 系统计,属性统计,生成有内容逻 辑关系的标签云,关键词云等

关系挖掘
给定两个或多个节点,发现他们之间的 关联关系。可用于推测不同经历内容 与岗位要求的匹配度等
多源异构数据的自采集、知识架构自构建
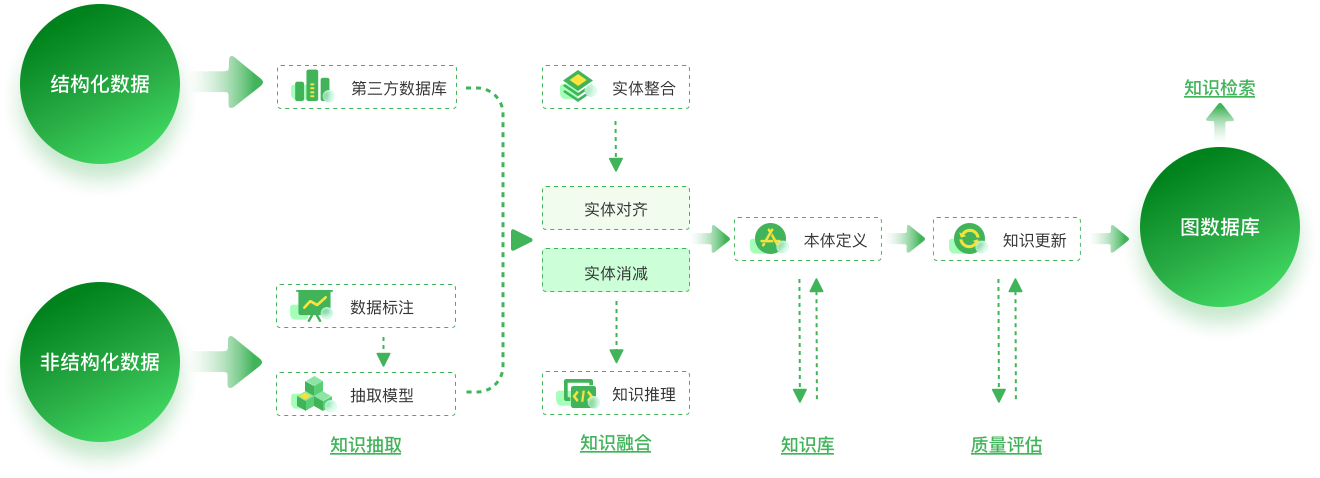
图谱构建流程
深耕人力资源场景,多任务赋能
应用场景
简历续写
基于知识图谱识别出续写引导句中的关键信息,并推理出逻辑相关的信...

自我评价
通过图谱识别工作经验中的关键键信息,并基于关键信息和他们之间的关...

岗位搜索
借助知识图谱中的知识推理,推理出与用户搜索岗位内容相关性高的信...

智能写JD
知识图谱的推理能力,可快速给用户输入的关键信息构建逻辑关系,并...

人才画像
基于图谱的知识抽取能力,准确识别简历中与经验相关信息及其类型...

简历分析
借助知识图谱的识别和推理能力,挖掘简历中丰富的隐藏信息,从信息...

人岗匹配
通过知识图谱对简历和JD内容的深度解读,从语义层面对两者内容进行...

简历生成
图谱的知识推理能力,可对用户输入关键词进行合理的拓展,最终生成...

岗位探测
基于图谱进行语义级别的内容匹配,可帮助用户同时在海量的岗位ID中...
知识增强的高质量NLP模型
核心功能

多模态图谱知识增强
与知识图谱中多模态信息相融合,借由其中所蕴涵的海量知识对模型生成的文本在事理性、逻辑性、真实性等方面的表现进行增强

预训练语言模型
符合pre-train标准,在海量数据集上充分的训练得到预训练语言模型,之后可通过fine-tune方式结合用户提供的特异化语料快速获取满足用户需求的上游应用。

基于语言学的知识增强
引入SRP(语义角色预测)预训练语言任务,使得模型在预训练阶段能够捕捉到更多的语义语法层面知识。

编码增强
采用词编码策略,使模型在编码层的处理更符合中国人表述习惯。同时还使用token的相对位置编码,使模型在长文本的情况下发挥更加稳定。

安全、可靠、高质量训练集
投入了大量的人力对原始语料进行手动处理,剔除掉语意不明、语法混乱、夹杂错字等问题的低质量语料。除此之外,还对语料中潜在的个人信息等敏感数据进行过滤处理。
多场景 高精度 强逻辑性
模型性能
小样本数据高精度训练结果
基于超15亿数据预训练后的模型,用户只需投入小规模人力资源场景的数据进行训练,即可得到精确度较高的生成结果。

知识增强提升内在逻辑性
通过RFKL范式下的融合网络,模型将经过知识图谱推理后的向量融入预训练语言模型的推理过程,并进行文本生成,使得生成内容更具内在逻辑性。

良好的多场景任务适应性
依靠RFKL范式构建的人力资源多模态语言模型,内含丰富的行业业务知识,可以支持多种行业场景下,不同的模型任务。

